LDAP API
Downloads
Getting Started
Documentation
- Five minute tutorial
- User Guide
- API 1 to 2 migration
- JavaDocs 2
- JavaDocs
- Cross-Reference 2
- Cross-Reference
- Developer Guide
- Internal Guide
Support
Community
About Apache
4 - ASN/1
To be completed…
The LDAP protocol is based on an ASN/1 description. We will notexplain in detail what is ASN/1 about, you would rather check This page for a very limited introduction, or if you feel teh need to understand what is ASN/1 in detail, just read the Olivier Dubuisson’s book on ASN.1 (This is probably the best reference !)
Anyway, we use a subset of ASN/1, as what we have to deal with is the BER/DER encoding. (BER or DER stands for Basic Encoding Rule and Distinguished Encoding Rule. There are other possible encoding, like PER, XER, CER, but they are irrelevant for LDAP)
What is needed to know is that ASN/1 is just a notation used to describe the messages being exchanged between a client and a server, and in order to use it, we need an encoder and a decoder on both sides :
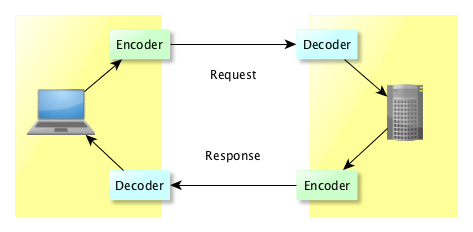
ASN/1 implementation in Apache LDAP API
It took a long time to get it right ! And it’s not perfect :-)
The very first iteration was using a proprietary library (IBM SNACC), but that was before ApacheDS became a TLP ! The next iteration was based on a rewriting system, which was pretty slow. Then came Snicker, a State Machine based decoder, which is currently what we use. We might change for a faster implementation, like what Kerby is using…
ASN/1 messages
Let’s start with the basic information.
An encoded ASN/1 message is a tuple containing two or three elements : a Type, a Length and optionally - ie if the length is not 0 - a Value. This tuple is called a TLV. Every message is a TLV.
But a message can have a complex structure, so a TLV itself can encapsulate some TLVs. Actually the V part can be a list of TLVs. This is recursive…
A typical encoded message can therefore represented this way :
[TL [TLV] [TL [TLV] [TLV]]]
Here, the message TLV value is a set of two TLVs, the second one being itself a composition of 2 TLVs.
The T describe the type of value, the L gives the length of this value (can be 0) and of course the V is the value, which can itself be a TLV.
Encoder/Decoder
There are two aspects we have to deal with :
- encoding messages
- decoding messages
Those are two different things, and we don’t use the same mechanism. Decoding is done using a State Machine, and Encoding is hard wired in each class implementing a message.
As we said, it’s not perfect, first because it’s complex to implement, complex to add a new message, and complex to test. We don’t have a compiler that generates the stubs to encode or decode messages. However the implemented logic should allow a compiler to generate a decoder without a lot of change.
Decoding
The Decoder work is to take a byte[] and transform it into an instance of a jave object. When we receive the byte[], we don’t know yet what kind of message we are dealing with, so the creation of the instance is differed.
We have built a generic decoder that takes some input and produces the result, based on those elements :
- A Grammar
- A Container
- A StateEnum
- A message interface and implementation which will contain the decoded message
- and optionally a Factory (for controls and extended operations)
The Grammar describes the transitions and actions of the state machine used to decode a message. Note that the actions can be stored in separate classes.
The Container is a wrapper around a message that is fed by the State Machine and that will contain the Java instance once fully decoded. It’s initally empty.
The StateEnum is a Java enumeration listing all the possible Grammar states, which are used in grammar’s transitions.
The interface and implementations respectively describe the accessors for a given element (Ldap message, control or extended operation), the implementation also provide the method to encode it.
The Factory is used to create the message instance (it’s used for controls and extended operations)
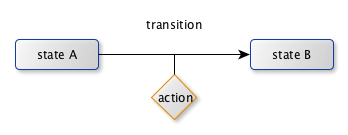
The state machine
So we decode a message using a state machine, which basically transit from one state to another, and optionally execute an action in between :
The difficulty with such a grammar is that transitions are to be defined for every cases. For instance, when it comes to process SearchRequest filters, here is what we get:
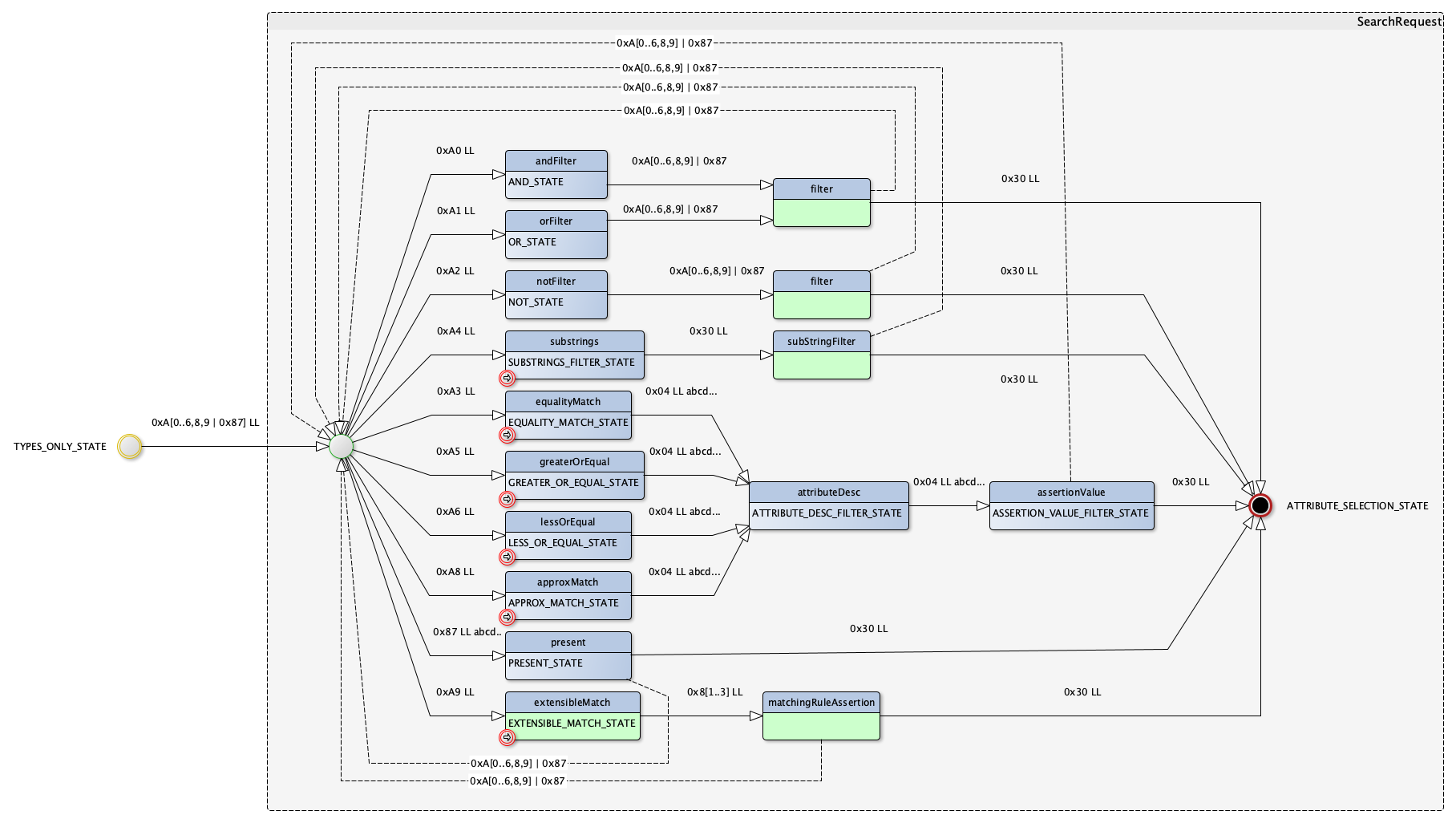
As we can see, we have many different possible transitions from the starting point, one per filter type.
Actually, we use the TLV tag to know which next step we should go to. Here, when we are on the Greater or Equal state, the transition to the Attribute Desc state is done if the tag is 0x04. If any other tag is met, then that should generate an error.
Error handling
So when we are expecting a specific tag (as seen previoulsy, 0x04, for instance), and we get another tag, we throw a DecoderException, and we stop the decoding. Of course, we have to discard all the PDU, and hopefully, we know how many bytes to process as it’s given in the first TLV.
Completed TLVs but incomplete message
Another use case is when we have completed a TLV, and there is another mandatory tag that follows. In the previous picture, the AttributeDesc state must be followed by a AssertionValue state (which starts with a 0x04 tag). If it’s not the case, then we should also issue an error.
Let’s say we have such a PDU:
...
0x63, 0x3D, // SearchRequest, 61 bytes long
0x04, 0x00, // Base Object RootDSE
0x0A, 0x01, 0x02, // Scope Base
0x0A, 0x01, 0x02, // Deref alias
0x02, 0x05, 0x00, 0x21, 0x6E, 0x00, 0x51, // SizeLimite
0x02, 0x02, 0x00, 0x03, // TimeLimit
0x01, 0x01, 0x41, // TypesOnly
0xA6, 0x04, // Less or equal filter, 4 bytes long
0x04, 0x02, // AttributeDesc
0x63, 0x6E, // cn
0x04, 0x1F, // AssertionValue, but out of the filter size...
0x00, 0x00, 0x00, 0x04, 0x04, 0x02, 0x04, 0x04,
0x30, 0x04, 0x04, 0x02, 0x04, 0x04, 0x30, 0x04,
0x04, 0x02, 0x2E, 0x26, 0x04, 0x03, 0x04, 0x04,
0x04, 0x12, 0x12, 0x12, 0x12, 0x12, 0x12,
...
The filter is a Less or equal (tags 0xA6). The gramar to get it decoded is:

Once we have decoded the AttributeDesc TLV (0x04 0x02 0x63 0x6E), we have consumed all the bytes for the Less or equal TLV, so the next 0x04 tag does not belong to the AssertionValue state, which also starts with a 0x04 tag, although this state is mandatory: we have an error. How do we detect it?
We have to start from the ASN1 grammar for this message:
...
SearchRequest ::= [APPLICATION 3] SEQUENCE {
baseObject LDAPDN,
scope ENUMERATED {
baseObject (0),
singleLevel (1),
wholeSubtree (2),
... },
derefAliases ENUMERATED {
neverDerefAliases (0),
derefInSearching (1),
derefFindingBaseObj (2),
derefAlways (3) },
sizeLimit INTEGER (0 .. maxInt),
timeLimit INTEGER (0 .. maxInt),
typesOnly BOOLEAN,
filter Filter,
attributes AttributeSelection }
...
Filter ::= CHOICE {
and [0] SET SIZE (1..MAX) OF filter Filter,
or [1] SET SIZE (1..MAX) OF filter Filter,
not [2] Filter,
equalityMatch [3] AttributeValueAssertion,
substrings [4] SubstringFilter,
greaterOrEqual [5] AttributeValueAssertion,
lessOrEqual [6] AttributeValueAssertion,
present [7] AttributeDescription,
approxMatch [8] AttributeValueAssertion,
extensibleMatch [9] MatchingRuleAssertion,
... }
...
AttributeValueAssertion ::= SEQUENCE {
attributeDesc AttributeDescription,
assertionValue AssertionValue }
...
AttributeDescription ::= LDAPString
-- Constrained to <attributedescription>
-- [RFC4512]
AttributeValue ::= OCTET STRING
The first TLV contains 8 internal TLVs, all mandatory, including the filter one. The Filter TLV is one TLV The LessOrEqual TLV has 2 TLVs, which are primitive types.
So in the case we are interested in, a _LessOrEqual* SearchRequest, we know that we expect this exact number of TLVs to be present. If the length of the encapsulating TLV is reached before we have consummed the expected number of TLVs, this is an error.
Somehow, it’s enough to count the expected TLVs to know if we are good to go, but it’s a bit trickier than that: some of the TLVs are optionals, and must not be counted. Also when a TLV encodes for a CHOICE, we may have a variable number of TLVs depending on the selected choice.
Another approach would be to consider that the grammar is a graph, and every SEQUENCE or SET element is a level. Keeping track of those level would allow the decoder to know if they are completed.
The biggest issue comes with OPTIONAL elements, which render the verification complex. For instance, such a grammar is hard to decode:
Control ::= SEQUENCE {
controlType LDAPOID,
criticality BOOLEAN DEFAULT FALSE,
controlValue OCTET STRING OPTIONAL }
FictiveMessage ::= SEQUENCE {
control Control,
value OCTET STRING }
}
We won’t be able to know if a OxO4 LL sequence is for a controlValue or a value, unless we check the number of consumed bytes and compare it with the SEQUENCE TLV length.
Now, the thing is that such a grammar is not a valid ASN.1 one: in this case, there is no way the decoder could decide which element is to be processed, either a controlValue or a value. In this case, we use a Application tag to determinate which one is to be processed:
Control ::= SEQUENCE {
controlType LDAPOID,
criticality BOOLEAN DEFAULT FALSE,
controlValue [0] OCTET STRING OPTIONAL }
FictiveMessage ::= SEQUENCE {
control Control,
value OCTET STRING }
}
The added [0] will encode the T part of the TLV differently (here, 0x40 for the controlValue [0] OCTET STRING, compared to 0x04 for the value OCTET STRING).
So in general, we always know how to transit from one element to the proper next one.
What if someone drafts a wrong PDU where an invalid element is injected? For instance, something like:
0x30, (byte)0x82, 0x30, 0x47, // 12 359 bytes long message
0x02, 0x02, 0x26, 0x2E, // message ID: 9774
0x63, 0x1F, // SearchRequest, 31 bytes long
0x04, 0x00, // Base Object RootDSE
0x0A, 0x01, 0x02, // Scope Base
0x0A, 0x01, 0x02, // Deref alias
0x02, 0x05, 0x00, 0x21, 0x6E, 0x00, 0x51, // SizeLimit
0x02, 0x02, 0x00, 0x03, // TimeLimit
0x01, 0x01, 0x41, // TypesOnly
-1-> (byte)0xA6, 0x04, // Less or equal filter
0x04, 0x02, // AttributeDesc
0x04, 0x04,
-2-> 0x04, 0x02, // AssertionValue, but out of the filter size...
-2-> 0x00, 0x00
0x30 ... // Attribute description list
Here, the four added bytes (in -2->) 0x04 0x02 0x00 0x00** are not part of the grammar, so they must be detected and discarded, because a previous alteration (in -1->) has made it so that the filter TLV only contains 4 bytes, and not 8.
Except that the grammar says that for a LessOrEqual filter, it expects two TLVs, one for the AttributeDesc, the second for AssertionValue, which is present, but not part of the filter’s TLV…
At this point, we know which is the parent’s TLV of each TLV. The -2-> TLV’s parent is the SearchRequest TLV (0x63 0x1F), when it should be -1-> (Less or equal filter, 0xA6 0x04).
The way to deal with such issue is to mark each transition for a given level as requiring a following TLV if there is a non optional element at the same level. If we exhaust the length of the parent’s TLV when we expect another TLV, that means we have an error. We just have to add this extra flag for each transaction that expect an extra TLV to be seen, and check it if the parent’s expected length is 0.
Second use case
Here is a PDU that is not valid, related to a SearchRequest:
0x30, 0x60, // LDAPMessage ::=SEQUENCE {
0x02, 0x01, 0x01, // messageID
0x63, 0x5A, // CHOICE { ..., searchRequest SearchRequest, ...
// SearchRequest ::= APPLICATION[3] SEQUENCE {
0x04, 0x1F, // baseObject LDAPDN,
'u', 'i', 'd', '=', 'a', 'k', 'a', 'r', 'a', 's', 'u', 'l', 'u', ',',
'd', 'c', '=', 'e', 'x', 'a', 'm', 'p', 'l', 'e', ',', 'd', 'c', '=', 'c', 'o', 'm',
0x0A, 0x01, 0x01, // scope ENUMERATED {
// singleLevel (1),
0x0A, 0x01, 0x03, // derefAliases ENUMERATED {
// derefAlways (3) },
0x02, 0x02, 0x03, ( byte ) 0xE8, // sizeLimit INTEGER (0 .. maxInt), (1000)
0x02, 0x02, 0x03, ( byte ) 0xE8, // timeLimit INTEGER (0 .. maxInt), (1000)
0x01, 0x01, ( byte ) 0xFF, // typesOnly BOOLEAN, (TRUE) filter Filter,
( byte ) 0xA4, 0x0D, // Filter ::= CHOICE {
// substrings [4] SubstringFilter
// }
// SubstringFilter ::= SEQUENCE {
0x04, 0x0B, // type OCTET STRING,
'o', 'b', 'j', 'e', 'c', 't', 'c', 'l', 'a', 's', 's',
// Here, we are expecting the Substrings part, a combinaison of initial, some any and final
// Instead we have a
0x30, 0x15, // AttributeSelection ::= SEQUENCE OF selector OCTET STRING
0x04, 0x05,
'a', 't', 't', 'r', '0', // selector
0x04, 0x05,
'a', 't', 't', 'r', '1', // selector
0x04, 0x05,
'a', 't', 't', 'r', '2' // selector
The problem is that the Subtrings filter has a length of 13 (0x0D), which imply we don’t have a initial, any or final element. The RFC 4511 is pretty clear. First the grammar says:
substrings SEQUENCE SIZE (1..MAX) OF substring CHOICE {
initial [0] AssertionValue, -- can occur at most once
any [1] AssertionValue,
final [2] AssertionValue } -- can occur at most once
The SEQUENCE must have a size of 1, which means at least one of the initial, any and final must be present.
Second the specification says:
"There SHALL be at most one 'initial' and at most one 'final' in the
'substrings' of a SubstringFilter. If 'initial' is present, it SHALL
be the first element of 'substrings'. If 'final' is present, it
SHALL be the last element of 'substrings'."
So that means we must have at least one of the three elements, in a specific order (0 or 1 initial first, 0 to many any and 0 or 1 final).
We can check if we have more than one initial or final in the grammar: we don’t have a transition from initial to initial, nor a transition from final to final, not a transition for final to any or from any to initial, or from final to initial. That covers the ordering and occurence constraints.
But we don’t have any rule that checks we have at least one of the three. One way to do that is to check the TLV length when we call the transition’s action:
public void action( C container ) throws DecoderException
{
TLV tlv = container.getCurrentTLV();
// The Length should not be null
if ( tlv.getLength() == 0 )
{
String msg = I18n.err( I18n.ERR_01101_NULL_LENGTH );
LOG.error( msg );
// This will generate a PROTOCOL_ERROR
throw new DecoderException( msg );
}
}
Here, if we have a 0x30 0x00 value for the substrings TLV, that means we don’t have any of initial, any or final, so we stop the decoding.
Encoding
It’s slightly simpler : we use the message or element implementation to encode a message.
The initial idea was to allocate a buffer to store the message, with the correct size, which required:
- A call to a method int computeLength() which would recursively encode each part, and compute their atomic size
- A call to a method ByteBuffer encode( ByteBuffer ) which would use the computed size and encoded atomic elements to allocate the proper buffer and store the type, length and data into this buffer.
This approach works, but creates many intermediate buffers used to store the encoded elements, and keep them until we have completed the full message encoding in order to know the required buffer size.
A better approach is now used:
- we preallocate a 1Kb buffer (LDAP messages are typically small)
- we encode recusively each part of a message, starting from the end, and store the result starting from the end of the buffer.
- if the buffer is not big enough, we reallocate a bigger one.
Despite the extra reallocations, it’s 2 times faster on average than the other approach, which requires an allocation for each single element we store.
Also we know the exact length of each part as we go on, which is not the case for the previous mechanism: we don’t anymore require a computeLengh() method.
This is the way we encode an ASN.1 element in the current implementation.
Let’s see with a simple exemple.
ASN.1 encoding a LDAP Simple Bind Request Message
Here is the LDAP grammars elements we are going to use:
LDAPMessage ::= SEQUENCE {
messageID INTEGER (0 .. maxInt),
protocolOp CHOICE {
bindRequest BindRequest,
...
BindRequest ::= [APPLICATION 0] SEQUENCE {
version INTEGER (1 .. 127),
name OCTET STRING,
authentication AuthenticationChoice }
AuthenticationChoice ::= CHOICE {
simple [0] OCTET STRING,
...
}
Here, we will use the following values:
- messageId: 1
- version : 3
- name: uid=akarasulu,dc=example,dc=com
- simple (aka password): password
Which gives:
MessageType : BIND_REQUEST
Message ID : 1
BindRequest
Version : '3'
Name : 'uid=akarasulu,dc=example,dc=com'
Simple authentication : '(omitted-for-safety)'
(the ‘password’ part is not exposed)
Here is the stack trace when we call the LdapEncoder.encodeMessage() function on this message:
encodeMessage()
encodeProtocolOp()
BindRequestFactory.INSTANCE.encodeReverse()
BerValue.encodeOctetString( buffer, ( byte ) LdapCodecConstants.BIND_REQUEST_SIMPLE_TAG, bindMessage.getCredentials() ) // encode the password
BerValue.encodeOctetString( buffer, bindMessage.getName() ) // encode the name
BerValue.encodeInteger( buffer, 3 ) // The LDAP version, 3
BerValue.encodeSequence( buffer, LdapCodecConstants.BIND_REQUEST_TAG, start ) // The encapsulating BindRequest tag and length
BerValue.encodeInteger( buffer, message.getMessageId() ) // The message ID, 1
BerValue.encodeSequence( buffer ) // The encapsulating LdapMessage tag and length
Then we get the resulting buffer, move the content to the position 0, which finally get a buffer containing the following bytes:
0x30, 0x33, // LDAPMessage ::=SEQUENCE {
0x02, 0x01, 0x01, // messageID MessageID
0x60, 0x2E, // CHOICE { ..., bindRequest BindRequest, ...
// BindRequest ::= APPLICATION[0] SEQUENCE {
0x02, 0x01, 0x03, // version INTEGER (1..127),
0x04, 0x1F, // name LDAPDN,
'u', 'i', 'd', '=', 'a', 'k', 'a', 'r', 'a', 's', 'u', 'l', 'u', ',',
'd', 'c', '=', 'e', 'x', 'a', 'm', 'p', 'l', 'e', ',', 'd', 'c', '=', 'c', 'o', 'm',
0x80, 0x08, // authentication AuthenticationChoice
// AuthenticationChoice ::= CHOICE { simple [0] OCTET STRING,
// ...
'p', 'a', 's', 's', 'w', 'o', 'r', 'd'
Note that each encode method will store the data at the end of the buffer:
Initial buffer
+-----------------------------------------------------------------------+
|.......................................................................|
+-----------------------------------------------------------------------+
After the credentials encoding:
+---------------------------------------------------------+--+-+--------+
|.........................................................|80|8|password|
+---------------------------------------------------------+--+-+--------+
^ ^ ^
| | |
| | +--------- The 'password' string
| |
| +----------- The password length, 8
|
+-------------- The tag, 0x80
After the name encoding:
+-------------------+--+--+-------------------------------+--+-+--------+
|...................|04|1F|uid=akarasulu,dc=example,dc=com|80|8|password|
+-------------------+--+--+-------------------------------+--+-+--------+
^ ^ ^
| | |
| | +-------- The name
| |
| +----------- The name length, 31
|
+-------------- The tag, 0x04 (OCTET STRING)
After the version encoding:
+------------+--+-+-+--+--+-------------------------------+--+-+--------+
|............|02|1|3|04|1F|uid=akarasulu,dc=example,dc=com|80|8|password|
+------------+--+-+-+--+--+-------------------------------+--+-+--------+
^ ^ ^
| | |
| | +--------- The version (3)
| |
| +----------- The version length, 1
|
+-------------- The tag, 0x02 (INTEGER)
After the BindRequest encoding:
+------+--+--+--+-+-+--+--+-------------------------------+--+-+--------+
|......|60|2E|02|1|3|04|1F|uid=akarasulu,dc=example,dc=com|80|8|password|
+------+--+--+--+-+-+--+--+-------------------------------+--+-+--------+
^ ^
| |
| +----------- The BindRequest length, 46 bytes
|
+-------------- The tag, 0x60 (BindRequest)
And finally, the full Ldap Message:
+---+--+--+--+--+--+-+-+--+--+-------------------------------+--+-+--------+
|...|30|33|60|2E|02|1|3|04|1F|uid=akarasulu,dc=example,dc=com|80|8|password|
+---+--+--+--+--+--+-+-+--+--+-------------------------------+--+-+--------+
^ ^
| |
| +----------- The BindRequest length, 46 bytes
|
+-------------- The tag, 0x60 (BindRequest)
last, not least, we move the whole data to pos 0, and set the buffer limit to the end of the encoded data:
+--+--+--+--+--+-+-+--+--+-------------------------------+--+-+--------+---+
|30|33|60|2E|02|1|3|04|1F|uid=akarasulu,dc=example,dc=com|80|8|password|...|
+--+--+--+--+--+-+-+--+--+-------------------------------+--+-+--------+---+
^
|
+-- limit
We can now send the encoded ASN1 buffer.